
Verifiable confidential computing for processing biometrics - Part I

Humanode is fundamentally constructed on the principle of privacy. Those of us involved in its development are dedicated to exceeding the current highest standards and making privacy available to all. Achieving true privacy, especially when personal data is involved, demands conscious and sustained effort - and the outcomes must be transparent so that anyone can verify them.
This is why we are embracing verifiable confidential computing for enhancing the security of biometric data. You might be wondering what it is and how it will improve the security. Well, this series of articles will be your technical guide to understanding all of it.
In the first part, we will discuss verifiable confidential computing and how it will help us secure users’ biometric data.
But before delving into the specifics, there's a critical point we'd like to highlight. We understand that there have been numerous considerations expressed about biometrics and its use for verification purposes. Concerns range from potential threats to anonymity, such as having to present one's face to a camera, to fears of misuse of biometric data, and even worries about Law enforcement intrusion. Someone for example raised a concern about this being against Satoshi’s vision.
We understand that there is genuine concern about the use of biometrics in Web3. And to mitigate the misconception, we have devised this series of articles to actually walk you through our unique approach to the Biometric verification process using verifiable confidential computing, aimed at slaking these concerns. By the end of this series, we are confident that you’ll be able to understand that:
I. Humanode’s private biometric authentication is anonymous and doesn’t link any personal information to a specific person.
II. No one, not even the Humanode team can access the raw biometric data in any condition whatsoever.
III. Biometrics is only used as an identifier to ensure that the person is a unique living human individual (to become a validator on the Humanode network or to prove that he is only using one Discord ID).
So let’s get on to it.
While we're confident in the robustness of our current solutions, we remain committed to pushing the boundaries of privacy protection, striving to deliver cutting-edge safeguards. At the same time, we firmly advocate for a 'Do Not Trust, Verify!’ approach, which is why we're dedicated to our implementation of verifiable private computing.
So what is verifiable private/confidential computing?
Verifiable Confidential Computing Defined
Confidential computing emerges as a revolutionary technology designed to resolve the tug-of-war between data privacy and its utility. This technology empowers us to perform processing on data without directly accessing the raw data itself. Furthermore, confidential computing offers irrefutable evidence that data confidentiality is maintained throughout the process.
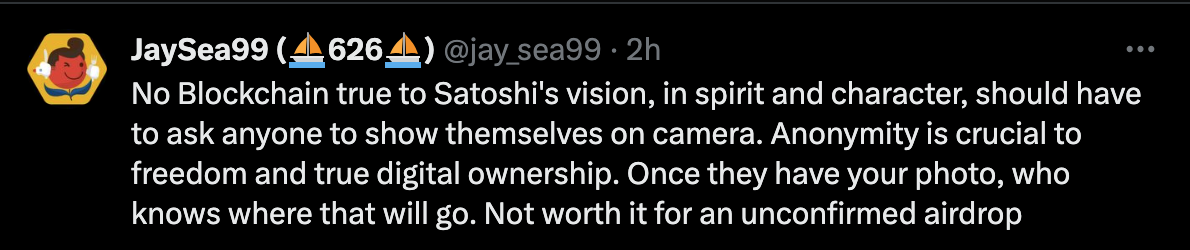
In simple words, confidential computing is a method to keep data private and encrypted while it’s being utilized. Computation of the data happens in a separate, secure environment that only allows approved code in and the approved results out.
This secure environment is usually a specific part of the server’s hardware with strong security and privacy protection and is called Trusted Execution Environment (TEE). A TEE can be a physically separate part of the server, but it’s often completely encased in a protected area inside the server’s main processor.
The Trusted Execution Environment (TEE) serves the function of providing a dedicated space for computations that is both isolated and verifiable. The isolation ensures it's disconnected from any other tasks occurring on the server. The verifiability allows you to identify the exact programs in operation within the TEE, reinforcing the privacy of the data.
While it's standard to encrypt data when stored or during transfer, the novelty of Confidential Computing lies in maintaining this encryption even when the data is in use and in the ability to verify the processing activity.
How do isolation and verification protect the data during computation?
Isolation and verification work together to create a secure environment for data processing. Verification ensures that the computation is doing exactly what it is supposed to do (ensure that a person is a unique human and isn’t already registered) and Isolation ensures that the specific computation is the only thing that accesses the data.
Let’s explore their role one by one:
Isolation
Isolation signifies that the rest of the server is blocked from accessing any activities occurring within the TEE, except via tightly controlled and restricted communication pathways. This sets it apart substantially from standard computational procedures.
Every modern server has a simple way to keep different tasks separate when they're running on a server chip, like a CPU. But this separation can fail if the server's Operating System gets messed up, which can happen quite often.
TEEs go a step further by creating an entirely separate system. They don't allow any information to pass through unless it's sent through specific communication channels. This means other tasks running on the same server can't access information that wasn't directly shared. In a TEE that's built into the hardware, the computer chip itself ensures this isolation. Specific commands tell the chip which areas to keep separate.
The isolation TEE provides can also be engineered to secure information stored in memory. The data a server is currently processing is stored in a place called working memory, or RAM. RAM hardware is usually produced by a different company than the one that makes the CPU, and it isn't part of the TEE.
Normal memory isolation can't always guarantee that it can stop other processes from peeking at or altering the data stored in memory.
To achieve strong isolation, the TEE encrypts information even while it's stored in working memory. This encryption is similar to the one used for protecting data stored on the hard disk, but the unique aspect of the TEE is that it uses encryption to safeguard the data even while it's being processed in working memory. This particular feature is exclusive to Confidential Computing.
Verification
Verification serves as the evidence a TEE provides to confirm its security. Also referred to as "attestation," it's akin to a detailed summary of all the pertinent data you require to ensure that it is indeed a secure and isolated zone.
Interacting with a TEE from the outside world is challenging by design, so the TEE has to validate two crucial aspects.
I. It must demonstrate that it's an authentic TEE, not an impostor pretending to be a TEE without providing actual isolation. This is termed "hardware identity".
II. It has to disclose specific details about the code that's operating within the TEE. This is known as the "hardware and software configuration".
Verifying the authenticity of the TEE (Hardware Identity)
To validate that you're indeed communicating with a real TEE, it furnishes verification about its type and if it is a confidential computing-enabled chip from a known provider.
The most crucial part of this verification is typically a cryptographic signature given by the hardware provider, confirming that it's a genuine TEE they manufactured. The manner in which the verification (or "attestation") is incorporated and the signature is included ensures that it's impossible to counterfeit or recreate signatures.
Hardware and Software configuration
To authenticate the code running within the TEE, the TEE generates a unique identifier, or "measurement" of the program housed in the TEE. This measurement is a compact value that distinctly identifies that specific program.
The measurement can be used to verify that the code operating in the TEE aligns with your intent: If you possess a copy of the program, you can compute its hash value, but a different program wouldn't yield the same hash value.
By contrasting the measurement offered by the TEE with a hash you computed independently, you can confirm their exact match and assure that the TEE is running the identical program.
This particular verification procedure — corroborating the appropriate code is operational, and validating the TEE itself — is termed remote attestation. The term "remote" in remote attestation indicates that it can be executed from any location: the signatures prevent a potential attacker in the middle from tampering, enabling you to inspect the measurements of TEEs that aren't locally available.
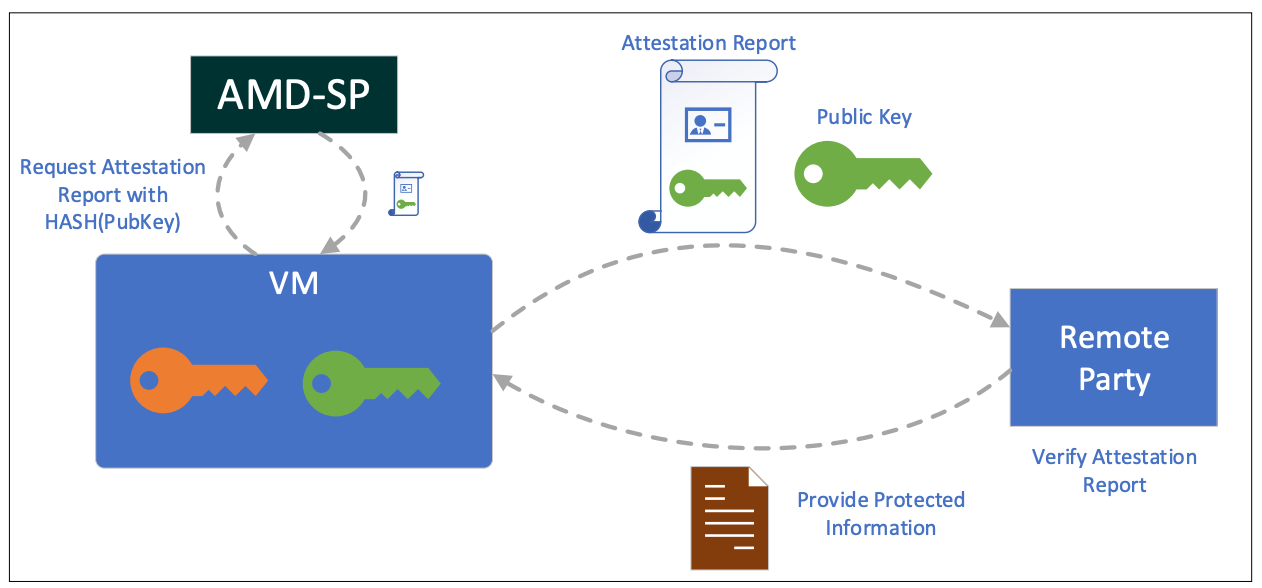
In the case of Humanode private biometric authentication, while configuring the server, we upload our initial image + OVMF. This initial image contains the guest VM code. At the end of the launch process, we send the signed identity block (IDB) containing the launch digest to VM.
The contents of this identity block allow the guest users to uniquely identify the VM. VM then asks SEV-SNP firmware for an attestation report. The attestation report contains IDB, the launch digest, and the data about the SEV-SNP platform.
The core purpose of this process is to verify and authenticate the VMs hardware and launch digest (software configuration).
In layman’s terms, we will use CVM utilizing AMD SEV-SNP to boot servers in such a way that after launching, it self-configures and self-executes to process and store the data in an encrypted form so that no one, not even we, can access or temper the data at any stage of the data-lifecycle be it data in use, data in transit or data at rest.
The isolation feature of the CVM allows us to keep the computation process private and confidential from other components. And the verification feature allows anyone to check that the computation applied to the biometric data is only meant to ensure that the data is from a unique entity.
So far, we looked into what Verifiable confidential computing is and how it helps in safeguarding the data from any unauthorized access during the processing.
To summarize, by using verifiable confidential computing, Humanode will ensure that all the computations on biometric data are performed in a trusted environment which ensures that no one can get their hands on the users' data even if they have physical access to the servers where the data is processed.
And that the computations performed on the data are verifiable so anyone can get an attestation report to verify that only computations happening on the data do what they are supposed to do.
By now, you must have gotten a bird’s eye view of the security and privacy offered by verifiable confidential computing. In the next part, we will discuss why our team decided to use it. Stay tuned for the next part!